Yifei Xu
E-mail : yifei.xu@weride.ai
Cell Phone : +1 (424) 535-6710
Personal Website : https://yfxu.top

E-mail : yifei.xu@weride.ai
Cell Phone : +1 (424) 535-6710
Personal Website : https://yfxu.top

The Center for Vision, Cognition, Learning, and Autonomy (VCLA) is affiliated with the Departments of Statistics and Computer Science at UCLA. We start from Computer Vision and expand to other disciplines. Our objective is to pursue a unified framework for representation, learning, inference and reasoning, and to build intelligent computer systems for real world applications.

Professor Wu is a professor of Statistics in University of California, Los Angeles. He is interested in statistical modeling, computing and learning. In particular, he is interested in generative models and unsupervised learning.
Shanghai Jiao Tong University
B. S. Eng. in Computer Science, Zhiyuan College
SJTU Excellent Bachelor's Degree Thesis (Top 1% in 3600 Undergraduates)

ACM Honored Class is a pilot computer science class in China.
Over the past 10 years, ACM students have received hundreds of honors and awards. ACM studnets won the ACM International Student Programming Contest World Championship for three times in 2002, 2005 and 2010.
ACM students has published more than 40 academic papers as the first author in the NIPS, WWW, SIGIR, SIGMOD, SIGKDD, ICML, AAAI and other important international conferences and journals.

Zhiyuan College, within Shanghai Jiao Tong University, is an institude that provides an Elite-education for our students. It aims to train them to become future leaders in science and in technology.
In order to be admitted to Zhiyuan College, a student must be on the top fo more than 17,000 undergraduate students within SJTU. Currently, 461 students are enrolled in Zhiyuan College.
By September 2016, 359 students have graduated from Zhiyuan College, 327 (91%) to pursue further studies, 273 (76%) admitted by world top 100 University listed in QS World University Ranking 2016, and 250 (70%) to pursue Ph.D. degrees.

Shanghai Jiao Tong University (SJTU), as one of the higher education institutions which enjoy a long history and a world-renowned reputation in China, is a key university directly under the administration of the Ministry of Education (MOE) of the People's Republic of China and co-constructed by MOE and Shanghai Municipal Government. SJTU has become a comprehensive, research-oriented, and internationalized top university in China.
GPA: 3.83 / 4.0 (Major GPA) (A+ = 4.3)

The CSST office administers the CSST Summer Program which brings outstanding third year undergraduate students, interested in PhD studies, nominated by top-tier universities in the People?s Republic of China (PRC) and Japan, to conduct 10 week intensive research training with UCLA faculty mentors. This 10-week program offers emerging scholars premier research training in a cutting edge scientific environment that fosters cross-disciplinary collaborations.
GPA: 4.0 / 4.0
Research Intern
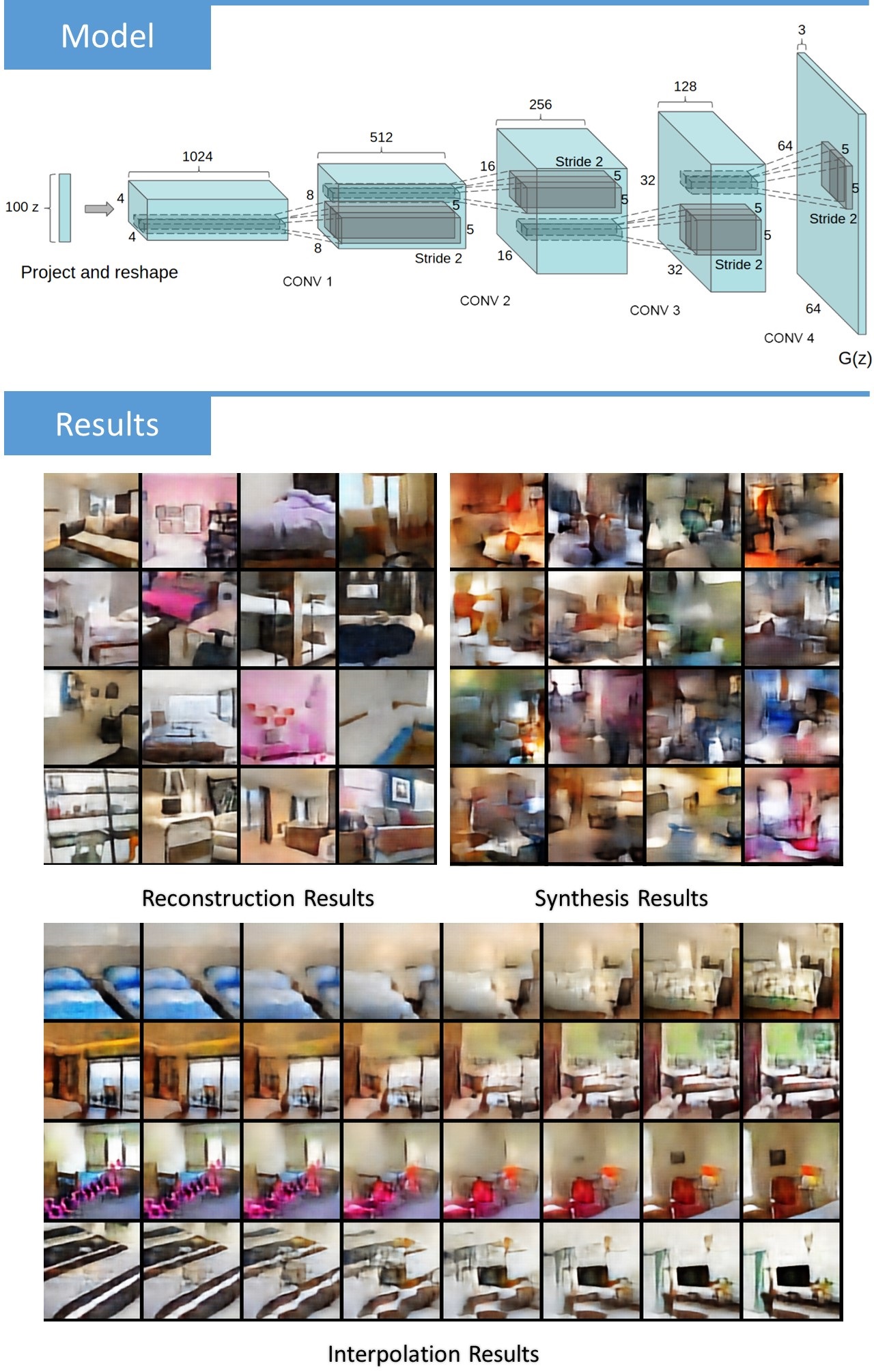
Paper Abstract
This paper proposes an alternating back-propagation algorithm for learning the generator network model. The model is a non-linear generalization of factor analysis. In this model, the mapping from the latent factors to the observed vector is parametrized by a convolutional neural network. The alternating back-propagation algorithm iterates between the following two steps: (1) Inferential back-propagation, which infers the latent factors by Langevin dynamics or gradient descent. (2) Learning back-propagation, which updates the parameters given the inferred latent factors by gradient descent.

Paper Abstract
This paper proposes a framework for generative learning of hierarchical structure of visual objects, based on training hierarchical random field models. The resulting model, which we call structured sparse FRAME model, is a straightforward variation on decomposing the original sparse FRAME model into multiple parts that are allowed to shift their locations, orientations and scales, so that the resulting model becomes a reconfigurable template.
Research Intern
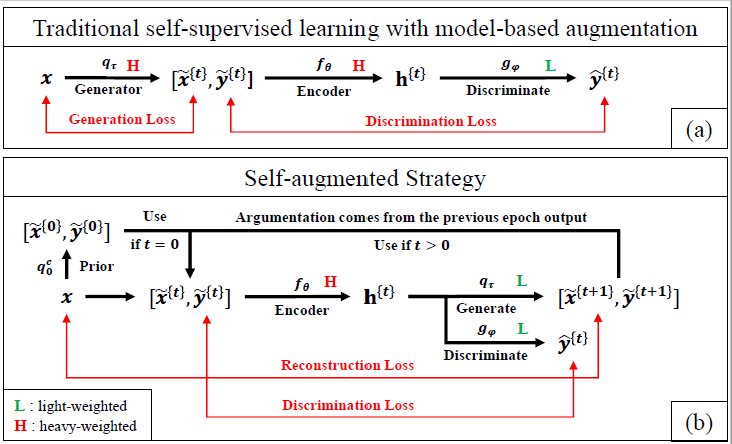
Paper Abstract
The core of a self-supervised learning method for pre-training language models includes the design of appropriate data augmentation and corresponding pre-training task(s). Most data augmentations in language model pre-training are context-independent. The seminal contextualized augmentation recently proposed by the ELECTRA requires a separate generator, which leads to extra computation cost as well as the challenge in adjusting the capability of its generator relative to that of the other model component(s). We propose a self-augmented strategy (SAS) that uses a single forward pass through the model to augment the input data for model training in the next epoch. Essentially our strategy eliminates a separate generator network and uses only one network to generate the data augmentation and undertake two pre-training tasks (the MLM task and the RTD task) jointly, which naturally avoids the challenge in adjusting the generator's capability as well as reduces the computation cost. Additionally, our SAS is a general strategy such that it can seamlessly incorporate many new techniques emerging recently or in the future, such as the disentangled attention mechanism recently proposed by the DeBERTa model. Our experiments show that our SAS is able to outperform the ELECTRA and other state-of-the-art models in the GLUE tasks with the same or less computation cost.
Research Intern
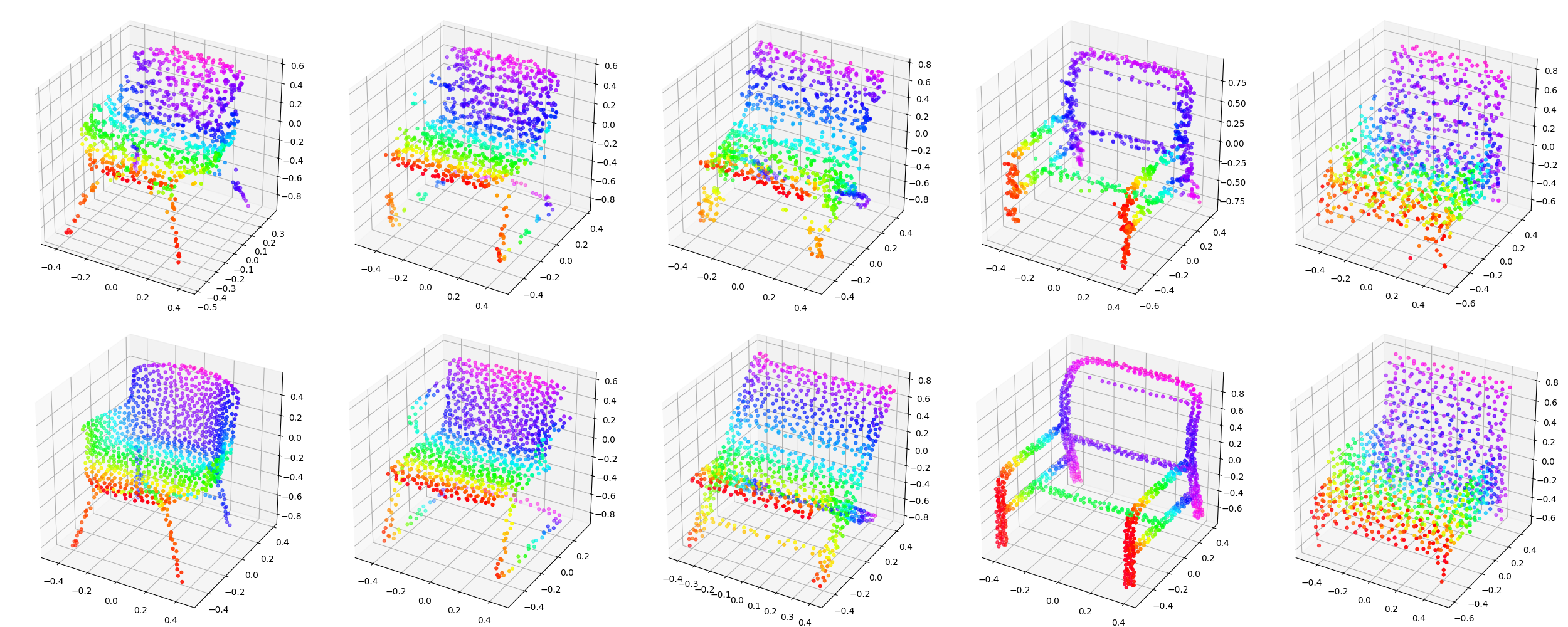
Paper Abstract
We propose a generative model of point clouds in the forms of an energy-based model, where the energy function is parameterized by an input-permutation-invariant bottom-up neural network. The energy function learns a coordinate encoding of each point and then aggregates all individual point features into an energy for the whole point cloud. We show that our model can be derived from the discriminative PointNet. The model is trained by MCMC-based maximum likelihood learning (as well as its variants), without the help of any assisting networks like those in GANs and VAEs. Our model does not rely on hand-crafting distance metric for point clouds in generation. It synthesizes point clouds that match to the observed examples. The learned point cloud representation can be useful for point cloud classification. Experiments demonstrate the advantages of the proposed model. Furthermore, we can learn a short-run MCMC toward the energy-based model as a flow-like generator for point cloud reconstruction and interpretation.
Research Intern
Paper Abstract
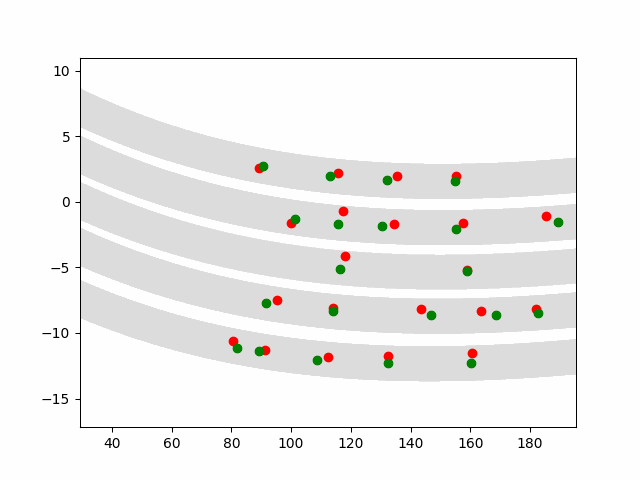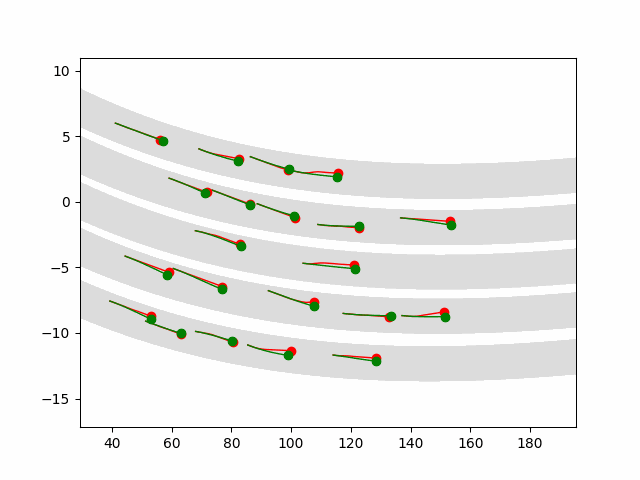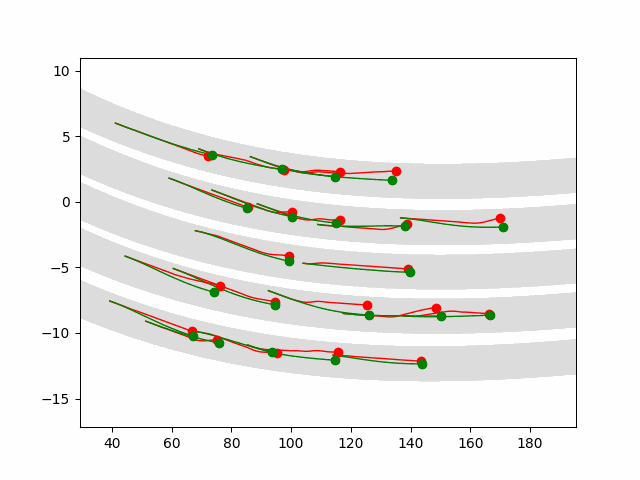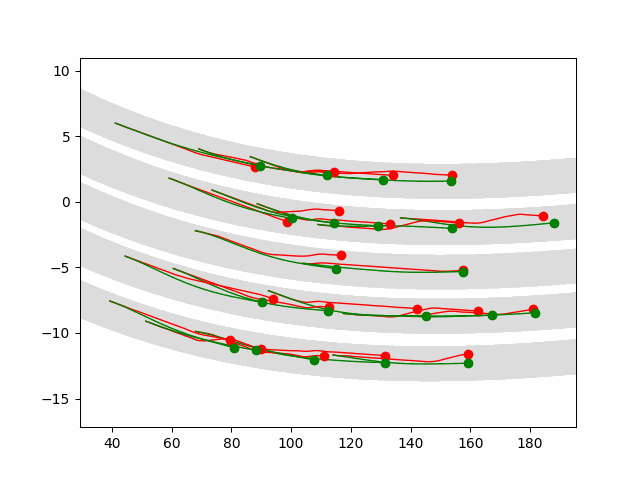
Autonomous driving is a challenging multiagent domain which requires optimizing complex, mixed cooperative-competitive interactions. Learning to predict contingent distributions over other vehicles' trajectories simplifies the problem, allowing approximate solutions by trajectory optimization with dynamic constraints. We take a model-based approach to prediction, in order to make use of structured prior knowledge of vehicle kinematics, and the assumption that other drivers plan trajectories to minimize an unknown cost function. We introduce a novel inverse optimal control (IOC) algorithm to learn other vehicles' cost functions in an energy-based generative model. Langevin Sampling, a Monte Carlo based sampling algorithm, is used to directly sample the control sequence. Our algorithm provides greater flexibility than standard IOC methods, and can learn higher-level, non-Markovian cost functions defined over entire trajectories. We extend weighted feature-based cost functions with neural networks to obtain NN-augmented cost functions, which combine the advantages of both model-based and model-free learning. Results show that model-based IOC can achieve state-of-the-art vehicle trajectory prediction accuracy, and naturally take scene information into account.
Research Assistant
 *1
*1
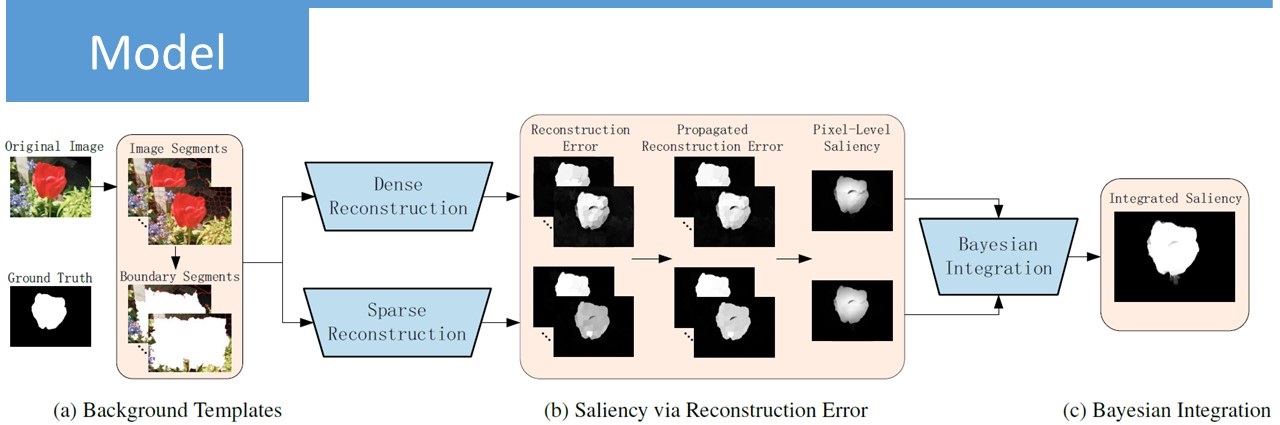
This is a competition hold by Alibaba. The goal is to output the picture with the most similarity by the given picture. The database is a million web pictures. There are three part for our model. They are saliency detection, CNN classification and text matching. I am in charge of saliency detection and classification. Our team ranked in the top 16 in the competition(Over 2000 teams).
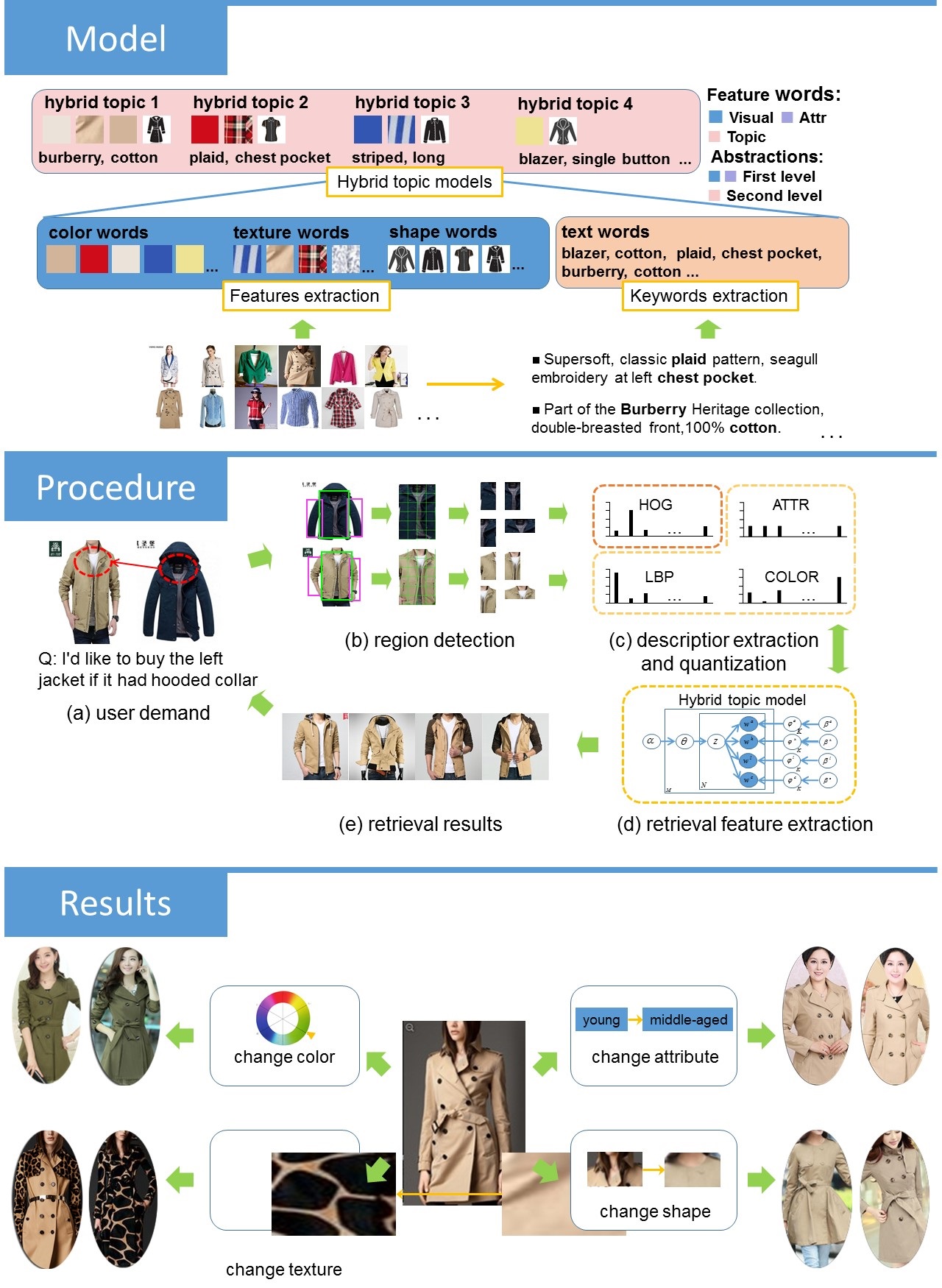
Paper Abstract
This paper proposes a novel approach to meet users' multi-dimensional requirements in clothing image retrieval.We propose the Hybrid Topic (HT) model to learn the intricate semantic representation of the descriptors above. The model provides an effective multi-dimensional representation of clothes and is able to perform automatic image annotation by probabilistic reasoning from image search. Furthermore, we develop a demand-adaptive retrieval strategy which refines users' specific requirements and removes users' unwanted features. Our experiments show that the HT method significantly outperforms the deep neural network methods.
Research Intern
 *2
*2
This work is based on "Joint cascade face detection and alignment" and "Unconstrained Face Alignment via Cascaded Compositional Learning". We aim to provide domain partition on the Joint cascade face detection and alignment method.
Yifei Xu, Zeng Huang, Ying Nian Wu, Sergey Tulyakov" Energy-based Implicit Function for 3D Shape Representation" In Review
Jianwen Xie, Yaxuan Zhu, Yifei Xu, Dingcheng Li, Ping Li " Generative Learning with Latent Space Flow-based Prior Model" In Proc. 37th AAAI Conference on Artificial Intelligence (AAAI) 2023
Yifei Xu†, Jingqiao Zhang†, Ru He†, Liangzhu Ge†, Chao Yang, Cheng Yang, Ying Nian Wu " SAS: Self-Augmented Strategy for Language Model Pre-training" In Proc. 36th AAAI Conference on Artificial Intelligence (AAAI) 2022
Yifei Xu†, Jianwen Xie†, Zilong Zheng, Song-Chun Zhu, Ying Nian Wu " Generative PointNet : Deep Energy-Based Learning on Point Sets for 3D Generation and Reconstruction" IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2021.
Yifei Xu, Jianwen Xie, Tianyang Zhao, Chris Baker, Yibiao Zhao, Ying Nian Wu " Energe-based Continous Inverse Optimal Control" IEEE Transactions on Neural Networks and Learning Systems (TNNLS) 2022; NeurIPS workshop on Machine Learning for Autonomous Driving, 2020
Tianyang Zhao, Yifei Xu, Mathew Monfort, Wongun Choi, Chris Baker, Yibiao Zhao, Yizhou Wang, Ying Nian Wu " Convolutional Spatial Fusion for Multi-Agent Trajectory Prediction" IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019.
Jianwen Xie, Yifei Xu, Erik Nijkamp, Ying Nian Wu, Song-Chun Zhu "Generative Hierarchical Structure Learning of Sparse FRAME Models" IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017.
Zhengzhong Zhou, Yifei Xu, Jingjin Zhou and Liqing Zhang "Interactive Image Search for Clothing Recommendation. " The 24th ACM international conference on Multimedia. ACM, 2016.
Academic Excellence Scholarship at SJTU Prize B, C, B (Top 10%, 20%, 10% in University)
Interdisciplinary Contest In Modeling 2016 Meritorious
UCLA CSST Scholarship and CSST Award (2 in CSST Program CS Major)
'ele' Scholarship for outstanding CS students (6 in university each year)
'YuanKang' Scholarship for outstanding research (5 in university each year)
SJTU Excellent Bachelor's Degree Thesis (Top 1% in 3600 Undergraduates)
Project of "Programming"
Project of "Programming Practice"
Project of "Data Struct" which include AVL tree, Hashmap, Linklist, etc.
A compiler which transform C code into MIPS code.
A virus runs on Linux in order to have the super authority.
Compress a trajectory with lossless and lossy method.
The implementation of "Recognizing Implicit Discourse Relations in the Penn Discourse Treebank".
Multiple machine learning algorithms including Regression, Clustering, Boostering, MCMC, VAE, GAN, EBM, EM ...
Multi-label text classification via ELMo and label attention
Including clustering algorithm, monte carlo algorithms, VAE, GAN, DCGAN, EBM, ABP, EM algorithm, etc.